
Conduit Nodes: How We Apply Web2 Horizontal Scaling Concepts Onchain
Learn how we apply web2 horizontal scaling techniques to blockchain nodes.


As a rollup platform, Conduit provides the infrastructure for teams to launch their own high-performance rollups, as well as the RPC node infrastructure for developers to build on those rollups.
The core challenge of RPCs is that blockchain nodes are designed to run independently, maintaining state and processing transactions in isolation. However, it’s becoming clear that the independent node paradigm struggles to meet the growing demand for scalable onchain infrastructure to power high-performance apps.
In order to solve this, Conduit applies horizontal scaling techniques already widely embraced in web2. We work to ensure the many nodes we run on each Conduit rollup can work together to process requests and maintain the consistency necessary to meet the demands of high-throughput applications. Below, we’ll explain how we work around the inherent design of blockchain nodes to achieve that.
The challenge: Onchain nodes don’t scale horizontally by default
Blockchain nodes are inherently stateful, meaning each node maintains its own copy of the blockchain state and executes transactions independently. While this ensures decentralization and trust, it also introduces several scaling challenges. Compute-intensive RPC requests place significant strain on nodes, often leading to slow response times. Additionally, as blockchains grow, their state size expands, making it harder to spin up new nodes quickly. And, when many nodes are deployed, some may fall behind during startup, resulting in inconsistent query results.
Another challenge is maintaining consistency across nodes when many are deployed. In a typical web2 cloud service, distributed databases can easily replicate and synchronize data. But on a blockchain, each node independently validates transactions and maintains state. If all of the nodes don’t remain perfectly synchronized, users will get inconsistent query results when interacting with them.
These problems get compounded when blockchains experience high traffic. Without proper scaling mechanisms in place, users are more likely to experience performance degradation and unreliable RPC responses.
Conduit’s approach tackles these issues by adapting cloud-native methodologies to blockchain node infrastructure. We focus on load balancing, caching, and request routing to ensure efficient distribution of workloads across different types of nodes optimized for different operations, while maintaining state consistency across all nodes.
Three key paths for RPC scaling across specialized nodes
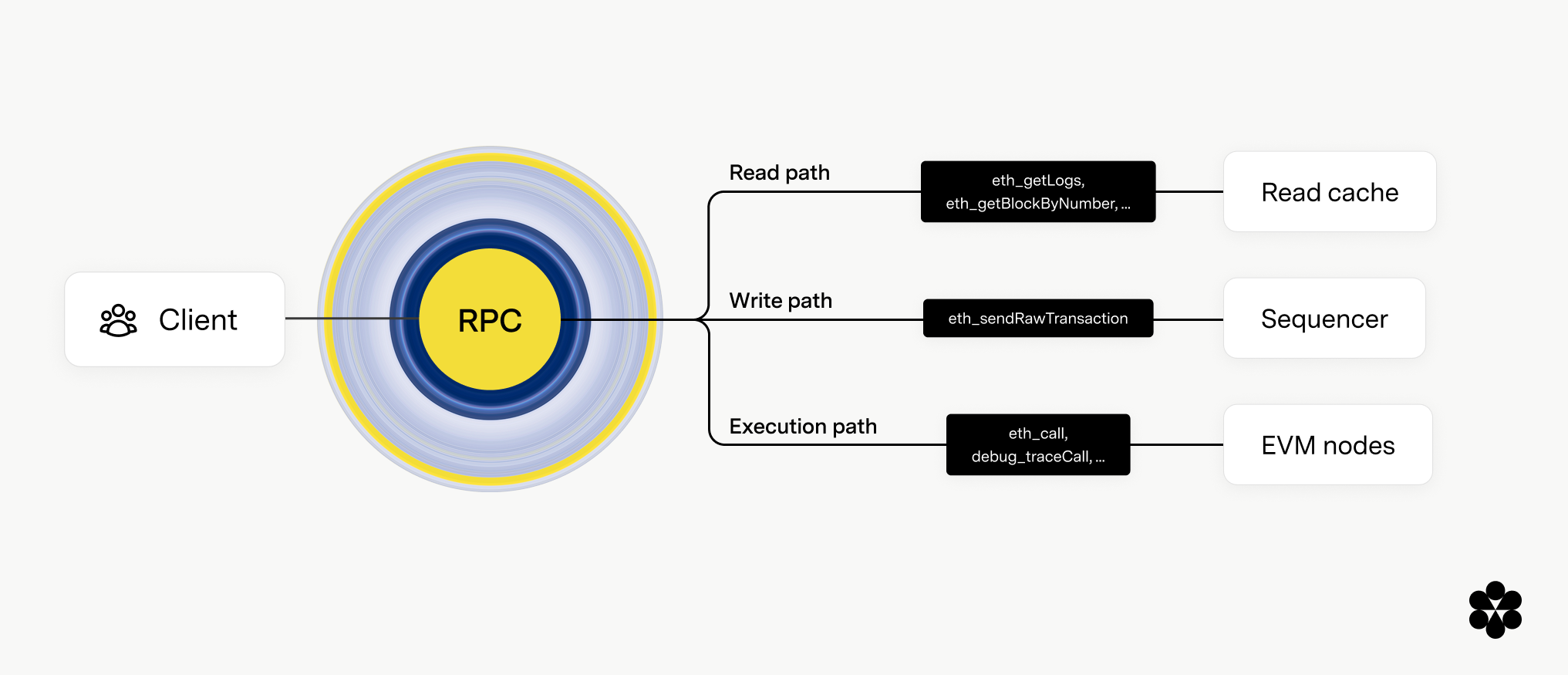
Our first solution for horizontal scaling onchain is to break down all RPC requests into three buckets, each with their own specialized path to a specific type of node. By deliberately routing different types of requests to the specific nodes best equipped to handle them, we’re able to limit the traffic sent to each individual node as much as possible, allowing them to maintain performance, while also ensuring requests are processed efficiently and limiting the number of full nodes we need to run.
The three paths and associated nodes for each type of RPC request are outlined below.
Let’s look more closely at each path below.
Write path: Routing transactions to the sequencer
In order to maintain both usability and the integrity of the blockchain, transactions need to be processed and finalized quickly, in the correct order, so that the blockchain state remains consistent across all nodes at all times. Conduit accomplishes that by routing all transaction RPC requests to the sequencer, as the sequencer is the node responsible for processing transactions and batching them for finalization on the settlement layer.
Since transactions are routed to the sequencer via the write path, the sequencer is also where we can implement tooling related to MEV, fraud protection, and other areas that touch transactions. For instance, if we want to mitigate MEV, we can tweak the sequencer to implement things like time-boosted transaction ordering, private mempools, or batch auctions.
Read path: Routing logs and receipts requests to replica nodes with cache layer
Read requests sent to RPC nodes such as fetching for logs and transaction receipts put a significant burden on nodes, and can cause performance degradation if not optimized properly – especially because read requests tend to come in large volumes. However, since these requests don’t alter the blockchain’s state, we don’t need to follow strict ordering rules in processing these requests.
Given that, we route read requests to many different replica nodes that we run on the rollup. Because we don’t need to enforce strict ordering for read requests the way we do for transactions, we can process read requests in parallel on all of the replica nodes running at any given time. This simultaneous execution and lack of bottlenecks allows us to execute read requests quickly.
Each replica node is optimized for the specific task of responding to read requests. For example, we cache frequently requested information like historical logs and receipts. By storing this information for fast access rather than loading it anew for each request, we can respond to each read request faster.
Another way we optimize replica nodes for read requests has to do with stateful operations. Some jsonrpc protocol methods rely on nodes tracking stateful information tied to previous client requests, such as active filters for eth_getFilterChanges. In a single-node setup, this data is stored locally, but in a horizontally scaled system, client requests can be routed to different nodes that don’t have access to that data, as it isn’t shared across nodes. This can lead to inconsistent responses to those requests, such as incomplete or missing data, because the request isn’t being handled by the original node. In order to solve this and scale stateful operations successfully, we move the state from individual replica nodes to a separate storage all nodes can access, so that this data can be shared across nodes as needed consistently.
Beyond these methods, the use of replica nodes specifically for read requests keeps other nodes clear for transactions and other, more execution-heavy request types.
Execution path: Routing EVM execution requests to EVM nodes
The third category of RPC requests includes execution-heavy requests for smart contract execution and state requests, which are among the most computationally heavy that we process. This includes requests like eth_call and debug_traceCall. Since these requests put such heavy strain on nodes, we distribute them across several EVM nodes designed for heavy compute, running software like Geth and Reth.
We use load balancing to spread execution requests across EVM nodes and limit the amount of computing power each one must expend at any given time. Additionally, we’ve made our own tweaks to Geth and Reth to improve performance and increase the throughput of execution requests each node can process.
Ensuring consistency across distributed nodes
Maintaining groups of nodes optimized for specific requests allows us to maintain performance. The next challenge after that is ensuring that we maintain consistency across those nodes, especially for the read and execution path. While traditional web2 databases can easily synchronize data across servers from a central authority, blockchain nodes have to remain in sync while independently verifying state transitions.
We employ several techniques to create consensus between nodes and cached data. This is straightforward for read path requests, because they’re served from a consistent cache layer that ensures all responses come from the same up-to-date data source.
For execution path requests, which require real-time blockchain state, we use a special consensus tracking mechanism that ensures all nodes agree on the most recent block within a strict time window. This prevents inconsistencies where one node might think a transaction is finalized while another does not. That ensures all nodes can serve requested data and represent the same state. As part of this, we also override special terms like "latest" and "finalized" to ensure they always reference the correct, agreed-upon block.
While we employ load balancing to avoid overwhelming nodes by distributing requests evenly across them, we employ smart routing for requests that uses sticky session logic to route requests from the same clients to the same nodes as much as possible for better consistency.
This task gets especially challenging when dealing with web socket jsonrpc requests and subscriptions, as it requires per-message routing instead of straight passthrough of websocket connections.
Preparing nodes for high-traffic events
Certain blockchain events, such as a token generation event (TGE), popular NFT mint, or price action triggering DeFi liquidations can create sudden surges in network traffic. Without proper preparation, these events can overload RPC infrastructure, leading to degraded performance or outright failures.
In order to mitigate this risk, we proactively scale up node resources ahead of anticipated demand surges where possible. We also have systems in place to monitor traffic patterns and improve our ability to anticipate unscheduled events that can cause RPC request increases. The load balancing techniques described previously are also important here for ensuring that requests are always distributed evenly across nodes when traffic spikes.
Another crucial tactic here includes autoscaling. Autoscaling is a failover strategy that ensures new nodes can be dynamically spun up when traffic increases, or if other nodes fail due to overload.
Unique considerations: Scaling older chains vs. newer chains
There are significant differences in the difficulty of scaling up an older, more active chain versus a newer one that may not be as widely adopted yet. Older chains are harder to scale, as the state size is much larger, meaning there’s more information for each new node added to ingest in order to get up to date. Newer chains have a smaller state, and are also more likely to have been designed from the outset with the latest scalability techniques and tooling in place.
Older chains also see more historical requests relating to older activity, which require more advanced caching techniques to handle. Their execution requests are also more likely to put more strain on RPC resources, as they are more likely to support bigger ecosystems of DeFi protocols and onchain applications. All of these considerations require further optimization so that nodes can perform regardless of the chain’s state size.
Horizontal scaling enables rollups to scale Ethereum
The demand for scalable blockchain infrastructure continues to rise, and rollups are meeting the challenge. But rollups alone aren’t enough – the RPC nodes developers need to build on and get information rollups are just as important. Horizontal scaling techniques like those described above enable Conduit to ensure that the rollups we power can perform under all conditions, and deliver on the promise of scaling Ethereum and supporting high-throughput apps onchain.